Paper Notes: Universal Sentence Encoder
Paper Notes: I’ve decided to read one paper every two weeks and post my notes here as a concrete deliverable. This is part of a habit I’d like to cultivate to read more books, academic papers, and industry blogs.
Summary
This paper describes the publicly-released Universal Sentence Encoder (for English). Building upon work on sentence encodings by Conneau et. al1 (May 2017), the authors make the following contributions:
- Demonstrating improved performance when using the Transformer architecture (introduced in June 2017)
- Detailing when it makes sense to use the simpler averaging architecture (DAN), which scales linearly with sentence length, instead of the Transformer, which scales quadratically
- Measuring large gains in transfer learning under constrained training data volumes compared to word embeddings alone
- Releasing the pretrained sentence encoder publicly on TF Hub
Notes
Model Training
- Input: lowercased PTB tokenized string
- Output: 512-dimensional sentence embedding
Two different models are built:
USE_T: Transformer-based encoder - the new, smarter, but more computationally demanding model.USE_D: Deep Averaging Network - the simpler but faster model, “whereby input embeddings for words and bi-grams are first averaged together and then passed through a feedforward deep neural network (DNN) to produce sentence embeddings.”
The authors train the encoders using multi-task learning for the following:
- Skip-Thought task (unsupervised): similar to skip-gram training of word embeddings, skip-thought training tries to teach the encoder to predict previous and future sentences around a given input sentence. One difference from skip-grams is that the number of possible sentences is far greater than that of possible words. To make the prediction task feasible, the encoder predicts the sentence word-by-word and is given the true words as teaching context.
- Email reply task (unsupervised): given an incoming email, this task aims to predict the reply.
- Classification tasks (supervised): these tasks use the Stanford Natural Language Inference (SNLI) corpus, “a collection of 570k human-written English sentence pairs manually labeled for balanced classification with the labels
entailment,contradiction, andneutral” (stanford.edu)
Experiments
Transfer Tasks
The authors run experiments across seven different transfer tasks (five for sentiment classification, one for topic classification, and one for similarity scoring).
They also use the Word Embedding Association Test (WEAT) to test model bias.
Model Axes for Comparison
The authors generated 14 models by varying the following axes:
USE_Dvs.USE_T: The Transformer performed better across the board. The largest gains of +7pp accuracy were seen when comparing the raw sentence encoder, without word embeddings.w2v w.e.vs.lrn w.e.(pretrained word embeddings vs. task-learned): Word-level transfer helped somewhat when task-specific data was very limited (+0pp to +3pp accuracy on SST 1k), but as expected this edge disappears when there’s enough task-specific data (-1pp accuracy on SST 67.3k).DANvs.CNN(for additional word embeddings): Depending on the task and the other axes, the CNN outperformed by a small amount (+0pp) to a large amount (+12pp).
The full model performance table shows that what works well in one task may not work well in another:
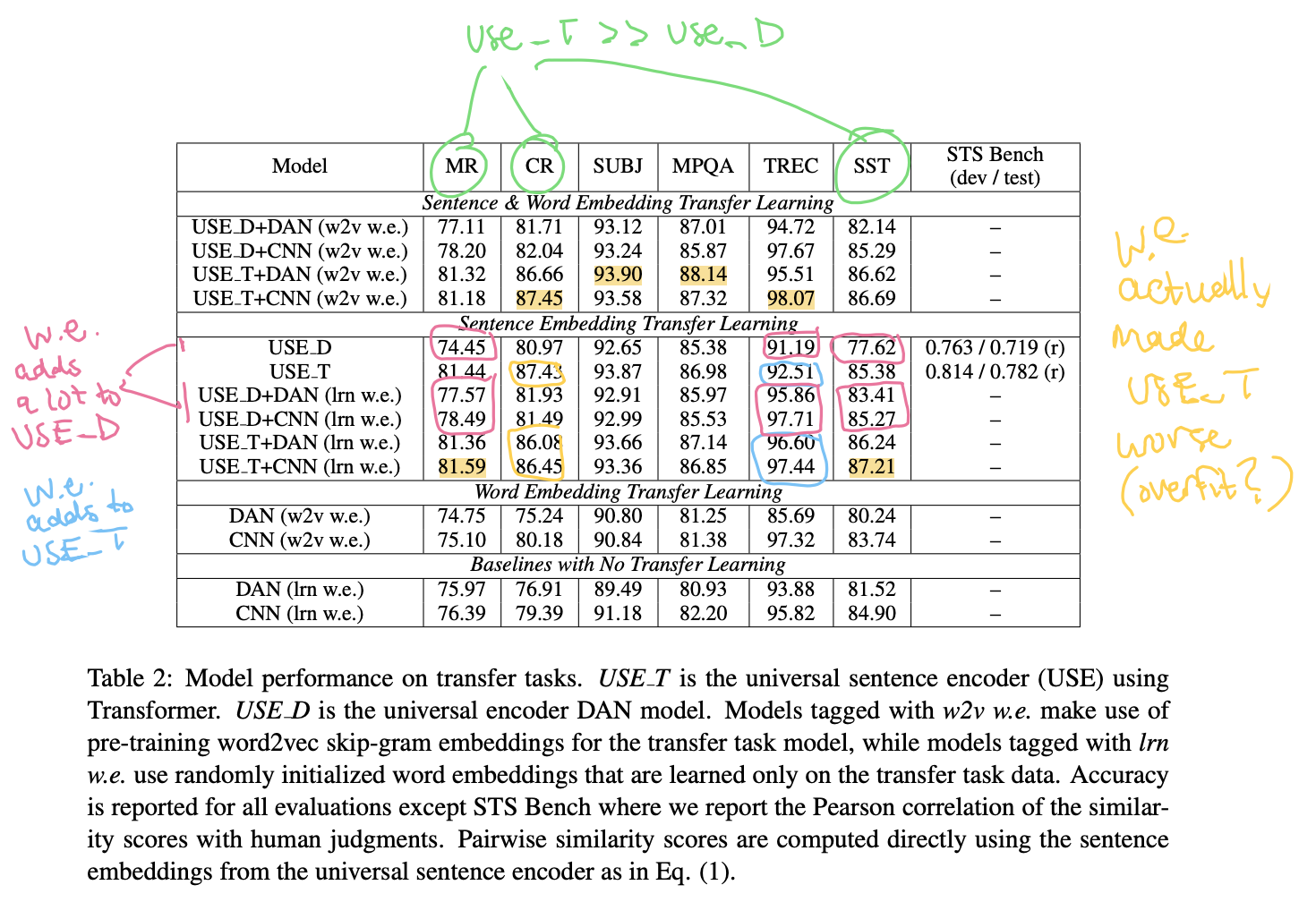
To simplify, let’s pick one of the transfer tasks to focus on. If we look at the SST task, for example, when using the best versions of the models and leverage all the training data we have, we see that pretrained word embeddings don’t help, but the sentence embeddings do improve upon the baseline:
| Category | Best Model on SST | Accuracy |
|---|---|---|
| Baselines with No Transfer Learning | CNN (lrn w.e.) | ~85% |
| Word Embedding Transfer Learning | CNN (w2v w.e.) | ~84% |
| Sentence Embedding Transfer Learning | USE T+CNN (lrn w.e.) | ~87% |
| Sentence & Word Embedding Transfer Learning | USE T+CNN (w2v w.e.) | ~87% |
Training Data Experiments
The authors test the transfer learning performance of the models when given different volumes of task-specific training data for fine-tuning.
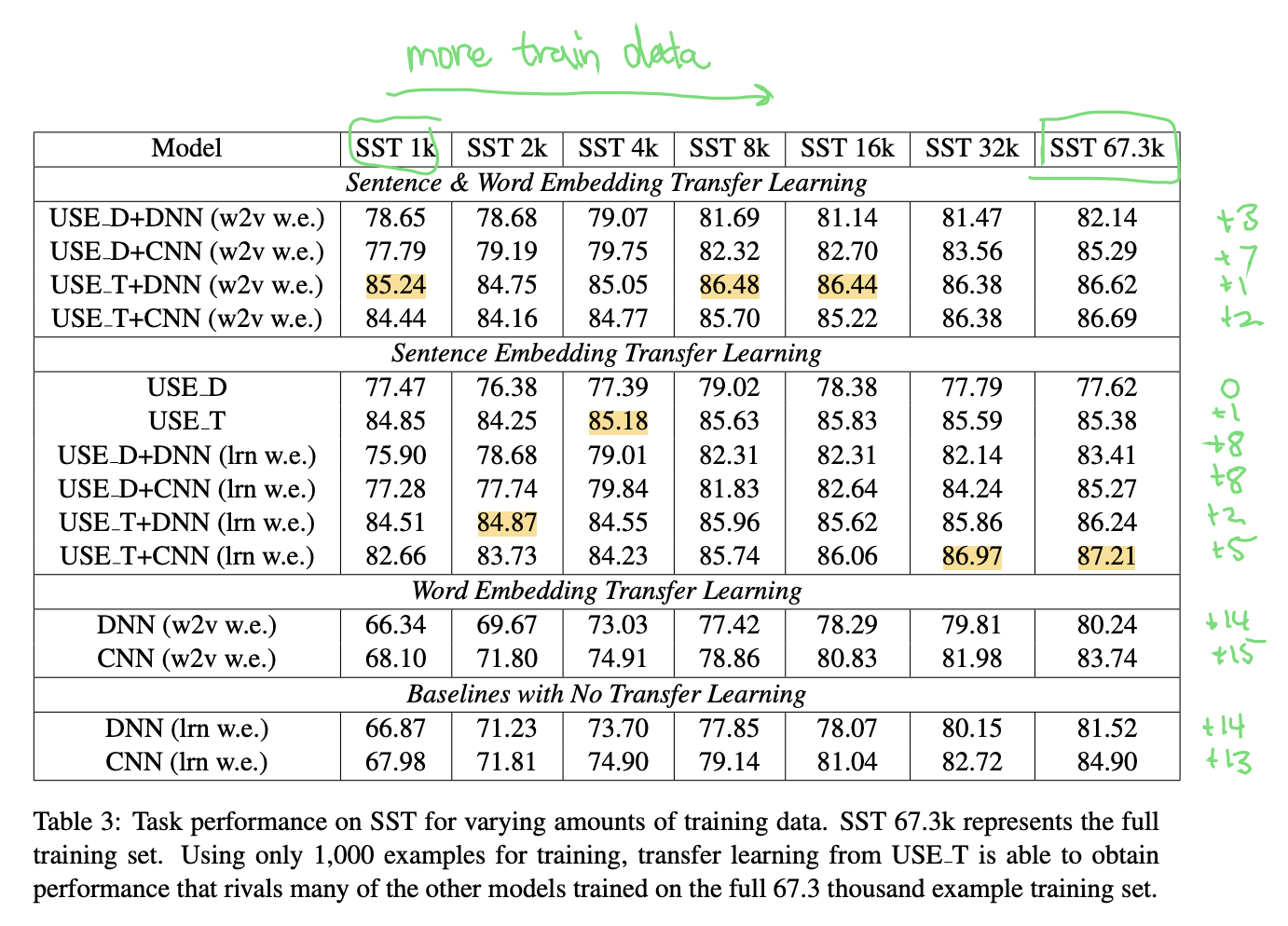
Scalability Experiments
The authors note that while USE_T performs better than USE_D, it does not scale well in terms of computation or memory. With respect to the number of words \(n\) per sentence, USE_T is \(O(n^2)\) and USE_D is \(O(n)\). For short sentences, USE_T and USE_D are similar, but for long sentences USE_T becomes impractical to use.
Thoughts
The main contribution of the authors in publishing this work is actually the universal sentence encoder itself; it has been downloaded over 1M times according to TF-Hub. However, it seems that from a research perspective it was more incremental, building upon Conneau et. al 2017 and Kiros et. al 20152. Seems those are the papers I should have read first.
-
Conneau, Alexis, Douwe Kiela, Holger Schwenk, Loic Barrault, and Antoine Bordes. 2017. “Supervised Learning of Universal Sentence Representations from Natural Language Inference Data.” arXiv [cs.CL].. ↩
-
Kiros, Ryan, Yukun Zhu, Russ R. Salakhutdinov, Richard Zemel, Raquel Urtasun, Antonio Torralba, and Sanja Fidler. 2015. “Skip-Thought Vectors.” In Advances in Neural Information Processing Systems, edited by C. Cortes, N. Lawrence, D. Lee, M. Sugiyama, and R. Garnett, 28:3294–3302. Curran Associates, Inc. ↩